I recently had the opportunity to speak at Spark Summit 2019 about one of the exciting machine learning projects that we’ve developed at Zynga. The title of my session was “Automating Predictive Modeling at Zynga with PySpark and Pandas UDFs” and I was able to highlight our first portfolio-scale machine learning project. The slides from my presentation are available on Google Drive.
While we’ve been known for our analytics prowess for over a decade, we’re now embracing machine learning in new ways. We’re building data products that scale to billions of events, tens of millions of users, hundreds of predictive signals, and dozens of games (portfolio-scale). We are leveraging recent developments in Python and Spark to achieve this functionality, and my session provided some details about our machine learning (ML) pipeline.
The key takeaways from my session are that recent features in PySpark enable new orders of magnitude of processing power for existing Python libraries, and that we are leveraging these capabilities to build massive-scale data products at Zynga. The goal of this post is to provide an overview of my session and details about our new machine learning capabilities.

I’m a distinguished data scientist at Zynga and a member of the analytics team, which spans our central technology and central data organizations. Our analytics team is comprised of the following groups:
Analytics Engineering: This engineering team manages our data platform and is responsible for data ingestion, data warehousing, machine-learning infrastructure, and live services powered by our data.
Game Analytics: This team consists of embedded analysts and data scientists that support our game development and game’s live services.
Central Analytics: Our central team focuses on publishing functions including marketing, corporate development, and portfolio-scale projects.
This team picture is from our annual team gathering, called Dog Days of Data.

Our portfolio of games includes in-house titles and games from recently acquired studios including Gram Games and Small Giant Games. Our studios are located across the globe, and most teams have embedded analysts or data scientists to support the live operations of our games. One of the goals for the central analytics team is to build data products that any of the games in our portfolio can integrate.

The scale and diversity of our portfolio presents several challenges when building large-scale data products. One of the common types of predictive models built by our data scientists are propensity models that predict which users are most likely to perform an action, such as making a purchase.
Our old approach for machine learning at Zynga was to build new models for each game and action to predict, and each model required manual feature engineering work. Our games have diverse event taxonomies, since a slots game has different actions to track versus a match-3 game or a card game.
An additional challenge we have is that some of our games have tens of millions of active users, generating billions of records of event data every day. This means that our predictive models need to scale beyond the single machine setups that we historically used when training models.

We’ve been able to use PySpark and new features on this platform in order to overcome all of these challenges. The main feature that I focused on for my Spark Summit session is Pandas UDFs (User-Defined Functions), which enable data scientists to use Pandas dataframes in a distributed manner. Another recent tool we’ve been leveraging is the Featuretools library, which we use to perform automated feature engineering. We use Databricks as our Spark environment, and have been able to combine all of these features into a scalable data pipeline that builds hundreds of propensity models daily.

We named the resulting data product AutoModel, because it has enabled us to automate most of the work involved in building propensity models for our games. This is the first portfolio-scale machine learning system at Zynga, which provides predictive models for every one of our games. Given the size of our portfolio and number of responses that we predict, the system generates hundreds of propensity models every day. We use the outputs of AutoModel to personalize our games and live services.

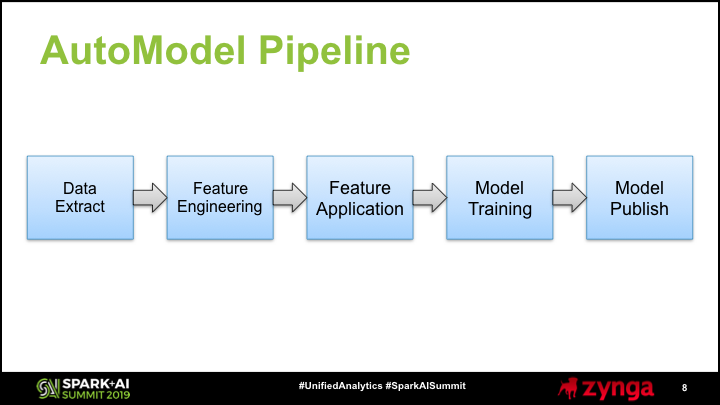
We used PySpark to build AutoModel as an end-to-end data product, where the input is tracking events in our data lake and the output is player records in our real-time database. This slide shows the main components of our Spark pipeline for AutoModel:
Data Extract: We query our data lake to return structured data sets with summarized event data and training labels.
Feature Engineering: On a sample of data, we perform automated feature engineering to generate thousands of features as input to our models.
Feature Application: We then apply these features to every active user.
Model Training: For each propensity model, we perform cross validation and hyperparameter tuning, and select the best fit.
Model Publish: We run the models on all active users and publish the results to our real-time database.
We’ll step through each of these components in more detail, and focus on the feature application step, where we apply Pandas UDFs.
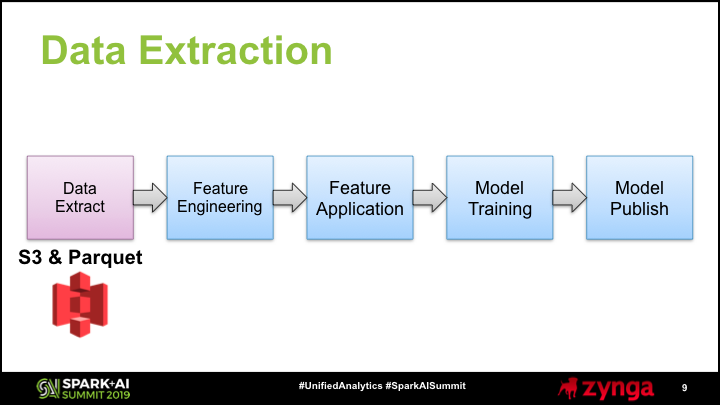
The first phase in our modeling pipeline is extracting data from our data lake and making it accessible as a Spark dataframe. In the initial step, we use Spark SQL to aggregate our raw tracking events into summarized events. The goal of this first step is to reduce tens of thousands of records per player to hundreds of records per player, to make the feature application step less computationally expensive. In the second step, we read in the resulting records from S3 directly in parquet format. To improve caching, we enabled the spark.databricks.io.cache.enabled flag.
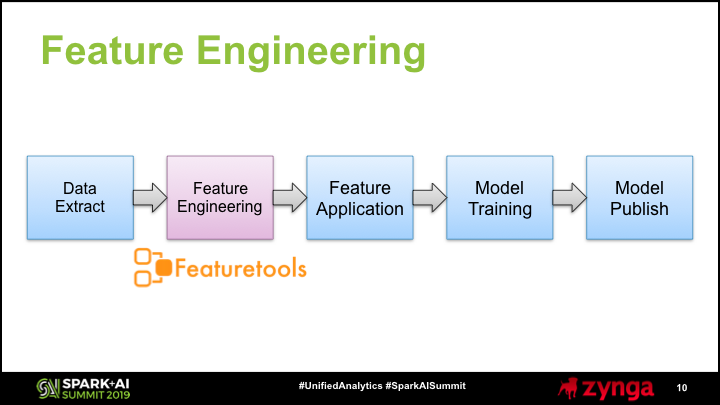
The second phase in the pipeline is performing automated feature engineering on a sample of players. We use the Featuretools library to perform feature generation, and the output is a set of feature descriptors that we use to translate our raw tracking data into per-player summaries.
Our primary goal with feature engineering is to translate the different events that occur within a game into a single record per player that summaries their gameplay activity. In our case, we are using structured data (tables) rather than unstructured data such as images or audio. The input is a table that is deep and narrow, which may contain hundreds of records per player and only a few columns, and the output is a shallow and wide table, containing a record per user with hundreds or thousands of columns. The resulting table can be used as input to train propensity models.
We decided to use automated rather than manual feature engineering, because we needed to build propensity models for dozens of games with diverse event taxonomies. For example, a match-3 game may record level attempts and resulting scores, while a casual card game may record hands played and their outcomes. We need to have a generalizable way of translating our raw event data into a feature vector that summarizes a player.

Use used the Featuretools library to automate feature engineering for our data sets. It is a python library that uses deep feature synthesis to perform feature generation. It is inspired by the feature generation capabilities in deep learning methods, but is focused on only feature generation and not model fitting. It generates a wide space of feature transformations and aggregations that a data scientist would explore when manually engineering features, but does so in a programmatic method.

One of the core concepts that the Featuretools library uses is entity sets, which identify the entities and relationships in a data set. You can think of entities as tables, and relationships as foreign keys in a database. The example below shows an entity set for customer and transaction tables, where each customer has zero or more transactions. Describing your data as an entity set enables Featuretools to explore transformations to your data across different depths, such as counting the number of transactions per customer or first purchase date of a customer.
One of the issues we faced when using this library is that entity sets are backed by Pandas dataframes, and therefore cannot natively be distributed when using PySpark.

Once you have represented your data as entity sets, you can perform deep feature synthesis to transform the input data sets into an output data set with a single record per target entity, which is a customer for our example. The code below shows how to load the Featuretoools library, perform deep features synthesis (dfs), and output a sample of the results.
The input to the feature synthesis function is an entity set and a target entity, which is used to determine how to aggregate features. This is typically the root node in your entity set, based on your foreign key constraints. The output of this code shows that a single record is created for each customer ID, and the columns include attributes from the customer table (zip code) and aggregated features from the related tables, defined here as the number and total value of transactions. If additional relationships are added to the entity set, even more features can be generated at different depths. In this case, the customer attributes are at depth 1 and the transaction attributes are at depth 2.

We use Featuretools in AutoModel to perform deep feature synthesis. One of the constraints that we had was that all of the inputs tables in our entity set need to be stored as a single table, and I’ll describe why we had this constraint later on. Luckily, our data is already in this format: each event has a player, category, and subcategory field, in additional to other columns that provide additional information. We defined relationships between these columns and split up the input data into multiple tables to define our entities. This allowed us to translate our input table representation into an entity set representation with a depth of 3.
For the feature generation phase, we use sampled data sets to ensure that Featuretools can run on a single machine, which is the driver node in our PySpark workflow. We also use a two-step encoding process that first performs 1-hot encoding on our input table and then performs deep feature synthesis on the encoded table.
The code snippet below shows some of the details involved in performing this transformation. We create an events entity set using our raw input data, using feature synthesis with a depth of 1 to create a set of feature descriptors (defs), and then use encode_features


































